
Використання дискримінантного аналізу для побудови торгових систем
- Вступ
- 1. Що ж таке - дискримінантний аналіз
- 2. Етапи дискримінантного аналізу
- 2.3. Аналіз отриманої моделі і її перевірка на тестових даних
- Висновок
Вступ
Одна з найважливіших завдань технічного аналізу - це визначити, в якому напрямку рушить ринок найближчим часом. З точки зору статистики завдання зводиться до того, щоб вибрати індикатори і визначити їх значення, на підставі яких можна було б розділити майбутній стан ринку на категорії: 1) рушить вгору, 2) рушить вниз.
Однак такий аналіз є порівняно складним і вимагає великої кількості даних на вході. Тому використання його в ручному режимі для аналізу руху ринку досить трудомістким. На щастя, з появою мови MQL5 і статистичних програм з'явилася можливість автоматизувати дії зі збору, підготовці даних і застосування до них дискримінантного аналізу.
У статті пропонується приклад створення радника для збору даних з ринку. Стаття є методичним посібником з використання дискримінантного аналізу в програмі Statistica для побудови прогностичних моделей для ринку FOREX.
1. Що ж таке - дискримінантний аналіз
Дискримінантний аналіз (далі ДА) відноситься до одного з методів розпізнавання образів. Можна сказати, що нейронні мережі є окремим випадком ТАК. Більшість успішних військових систем, що використовують розпізнавання образів, використовують саме ТАК.
ТАК дозволяє вирішити задачу про те, які змінні і як розділяють (дискримінують) вхідний потік даних на групи.
Розглянемо спрощений приклад використання ТАК для ринку FOREX. У нас є дані за значеннями індикаторів Relative Strength Index (RSI), MACD , Relative Vigor Index (RVI). Потрібно спрогнозувати напрямок, в якому рушить ціна. Виконавши ТАК, ми в підсумку можемо отримати наступне.
a. Індикатор RVI не допомагає робити прогноз. Виключаємо його з аналізу.
b. ТАК видав два дискримінантних рівняння:
- G1 = a1 * RSI + b1 * MACD + з1, рівняння для випадків, коли ціна рушила вгору;
- G2 = a2 * RSI + b2 * MACD + с2, рівняння для випадків, коли ціна рушила вниз.
Обчислюючи значення G1 і G2 на початку кожного бару, ми прогнозуємо, що якщо G1> G2, то ціна рушить вгору; якщо G1 <G2, то ціна рушить вниз.
ТАК може бути корисним для початкового знайомства з нейронними мережами. При використанні ТАК ми отримуємо рівняння, аналогічні тим, які розраховуються для роботи нейронних мереж. Це допомагає краще зрозуміти внутрішній їх пристрій, а також попередньо визначити, чи має сенс використовувати нейронні мережі в ваших стратегіях.
2. Етапи дискримінантного аналізу
Виконання аналізу можна розділити на кілька етапів.
- Підготовка данних;
- Вибір кращих змінних з підготовлених даних;
- Аналіз отриманої моделі і її перевірка на тестових даних;
- Побудова моделі на основі дискримінантних рівнянь.
Діскрімінатний аналіз включений практично в усі сучасні програмні пакети, призначені для статистичного аналізу даних. Найбільш популярними пакетами є Statistica (StatSoft Inc.) і SPSS (IBM Corporation). Далі ми будемо розглядати застосування дискримінантного аналізу за допомогою програми Statistica. Знімки екранів зроблені для версії Statistica 8.0. Приблизно також це виглядає і в більш ранніх версіях програми. Слід зауважити, що Statistica містить також багато інших корисних інструментів для трейдера, включаючи нейронні мережі.
2.1. підготовка даних
Збір даних залежить від поставленого завдання. Сформулюємо задачу в такий спосіб: використавши індикатори, спробуємо передбачити рух цінового графіка на барі наступному після бару, для якого значення індикаторів відомі. Для збору даних напишемо радник, який буде зберігати значення індикаторів і дані про ціну в файл.
Файл повинен бути в форматі CSV і мати наступну структуру. Змінні повинні бути розташовані в стовпчик, тобто кожному стовпчику відповідає будь-якої один індикатор. У рядках повинні розташовуватися послідовні вимірювання (випадки), тобто значення індикаторів для конкретних барів. Іншими словами, в заголовках таблиці по горизонталі розташовані індикатори, по вертикалі послідовні бари.
У таблиці повинна бути змінна, по якій буде виконуватися поділ на групи (групує змінна). У нашому випадку така змінна буде заснована на зміні ціни на наступному барі, що йде за баром для якого були отримані значення індикатора. Групує змінна повинна містити номер групи, до якої відносяться дані, що містяться в тій же рядку. Наприклад, номер 1 для випадків, коли ціна пішла вгору, і номер 2 для випадків, коли ціна пішла вниз.
Індикатори, значення яких нам знадобляться:
У функції OnInit () виробляється створення індикаторів (отримання хендлов індикаторів), створення файлу MasterData.csv і запис в нього заголовка стовпців даних:
int OnInit () {h_AC = (Symbol (), Period ()); h_BearsPower = (Symbol (), Period (), BearsPower_PeriodBears); h_BullsPower = (Symbol (), Period (), BullsPower_PeriodBulls); h_AO = (Symbol (), Period ()); h_CCI = (Symbol (), Period (), CCI_PeriodCCI, CCI_Applied); h_DeMarker = (Symbol (), Period (), DeM_PeriodDeM); h_FrAMA = (Symbol (), Period (), FraMA_PeriodMA, FraMA_Shift, FraMA_Applied); h_MACD = (Symbol (), Period (), MACD_PeriodFast, MACD_PeriodSlow, MACD_PeriodSignal, MACD_Applied); h_RSI = (Symbol (), Period (), RSI_PeriodRSI, RSI_Applied); h_RVI = (Symbol (), Period (), RVI_PeriodRVI); h_Stoch = (Symbol (), Period (), Stoch_PeriodK, Stoch_PeriodD, Stoch_PeriodSlow, MODE_SMA, Stoch_Applied); h_WPR = (Symbol (), Period (), WPR_PeriodWPR); if (h_AC == INVALID_HANDLE || h_BearsPower == INVALID_HANDLE || h_BullsPower == INVALID_HANDLE || h_AO == INVALID_HANDLE || h_CCI == INVALID_HANDLE || h_DeMarker == INVALID_HANDLE || h_FrAMA == INVALID_HANDLE || h_MACD == INVALID_HANDLE || h_RSI == INVALID_HANDLE || h_RVI == INVALID_HANDLE || h_Stoch == INVALID_HANDLE || h_WPR == INVALID_HANDLE) {Print ( "Помилка створення індикаторів"); return (1); } ArraySetAsSeries (buf_AC, true); ArraySetAsSeries (buf_BearsPower, true); ArraySetAsSeries (buf_BullsPower, true); ArraySetAsSeries (buf_AO, true); ArraySetAsSeries (buf_CCI, true); ArraySetAsSeries (buf_DeMarker, true); ArraySetAsSeries (buf_FrAMA, true); ArraySetAsSeries (buf_MACD_m, true); ArraySetAsSeries (buf_MACD_s, true); ArraySetAsSeries (buf_RSI, true); ArraySetAsSeries (buf_RVI_m, true); ArraySetAsSeries (buf_RVI_s, true); ArraySetAsSeries (buf_Stoch_m, true); ArraySetAsSeries (buf_Stoch_s, true); ArraySetAsSeries (buf_WPR, true); FileHandle = FileOpen ( "MasterData2.csv", FILE_ANSI | FILE_WRITE | FILE_CSV | FILE_SHARE_READ, ';'); if (FileHandle! = INVALID_HANDLE) {Print ( "FileOpen OK"); FileWrite (FileHandle, "Time", "Hour", "Price", "AC", "dAC", "Bears", "dBears", "Bulls", "dBulls", "AO", "dAO", "CCI "," dCCI "," DeMarker "," dDeMarker "," FrAMA "," dFrAMA "," MACDm "," dMACDm "," MACDs "," dMACDs "," MACDms "," dMACDms "," RSI ", "dRSI", "RVIm", "dRVIm", "RVIs", "dRVIs", "RVIms", "dRVIms", "Stoch_m", "dStoch_m", "Stoch_s", "dStoch_s", "Stoch_ms", "dStoch_ms "," WPR "," dWPR "); } Else {Print ( "Операція FileOpen невдала, помилка", GetLastError ()); ExpertRemove (); } Return (0); }У обробнику події OnTick () проводиться визначення надходження нового бару і збереження даних в файл.
Рух ціни будемо визначати за останнім сформованому бару, а значення індикаторів беремо з попереднього бару. Крім абсолютного значення індикатора зберігаємо його різницю з попереднім значенням, щоб враховувати напрямок його зміни. Такі змінні в запропонованому прикладі матимуть в назві префікс "d".
Для індикаторів з сигнальною лінією зберігаємо різницю між головною і сигнальною лінією, а також її динаміку. Додатково зберігаємо час надходження бару і значення години для нього. Це може стати в нагоді для фільтрації даних за часом.
Таким чином, ми будемо враховувати 37 показників, щоб побудувати модель прогнозування руху ціни.
void OnTick () {static datetime Prev_time; MqlRates mrate []; MqlTick tickdata; ArraySetAsSeries (mrate, true); if (! SymbolInfoTick (_Symbol, tickdata)) {Alert ( "Помилка оновлення котирувань - помилка:", GetLastError (), "!!"); return; } If (CopyRates (_Symbol, _Period, 0, 4, mrate) <0) {Alert ( "Помилка копіювання історичних котирувань - помилка:", GetLastError (), "!!"); return; } If (Prev_time == mrate [0] .time) return; Prev_time = mrate [0] .time; bool copy_result = true; copy_result = copy_result && FillArrayFromBuffer1 (buf_AC, h_AC, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_BearsPower, h_BearsPower, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_BullsPower, h_BullsPower, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_AO, h_AO, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_CCI, h_CCI, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_DeMarker, h_DeMarker, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_FrAMA, h_FrAMA, 4); copy_result = copy_result && FillArraysFromBuffers2 (buf_MACD_m, buf_MACD_s, h_MACD, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_RSI, h_RSI, 4); copy_result = copy_result && FillArraysFromBuffers2 (buf_RVI_m, buf_RVI_s, h_RVI, 4); copy_result = copy_result && FillArraysFromBuffers2 (buf_Stoch_m, buf_Stoch_s, h_Stoch, 4); copy_result = copy_result && FillArrayFromBuffer1 (buf_WPR, h_WPR, 4); if (! copy_result == true) {Print ( "Помилка копіювання даних"); return; } If (FileHandle! = INVALID_HANDLE) {MqlDateTime tm; TimeCurrent (tm); uint Result = 0; Result = FileWrite (FileHandle, TimeToString (TimeCurrent ()), tm.hour, (mrate [1] .close-mrate [2] .close) / _Point, buf_AC [2], buf_AC [2] -buf_AC [3], buf_BearsPower [2], buf_BearsPower [2] -buf_BearsPower [3], buf_BullsPower [2], buf_BullsPower [2] -buf_BullsPower [3], buf_AO [2], buf_AO [2] -buf_AO [3], buf_CCI [2], buf_CCI [2] -buf_CCI [3], buf_DeMarker [2], buf_DeMarker [2] -buf_DeMarker [3], buf_FrAMA [2], buf_FrAMA [2] -buf_FrAMA [3], buf_MACD_m [2], buf_MACD_m [2] - buf_MACD_m [3], buf_MACD_s [2], buf_MACD_s [2] -buf_MACD_s [3], buf_MACD_m [2] -buf_MACD_s [2], buf_MACD_m [2] -buf_MACD_s [2] -buf_MACD_m [3] + buf_MACD_s [3], buf_RSI [2], buf_RSI [2] -buf_RSI [3], buf_RVI_m [2], buf_RVI_m [2] -buf_RVI_m [3], buf_RVI_s [2], buf_RVI_s [2] -buf_RVI_s [3], buf_RVI_m [2] - buf_RVI_s [2], buf_RVI_m [2] -buf_RVI_s [2] -buf_RVI_m [3] + buf_RVI_s [3], buf_Stoch_m [2], buf_Stoch_m [2] -buf_Stoch_m [3], buf_Stoch_s [2], buf_Stoch_s [2] - buf_Stoch_s [3], buf_Stoch_m [2] -buf_Stoch_s [2], buf_Stoch_m [2] -buf_Stoch_s [2] -buf_Stoch_m [3] + b uf_Stoch_s [3], buf_WPR [2], buf_WPR [2] -buf_WPR [3]); if (Result == 0) {Print ( "При виконанні FileWrite виникла помилка", GetLastError ()); ExpertRemove (); }}}Після запуску радника в папці: каталог_данних_термінала / MQL5 / Files буде створений файл MasterData.CSV. При запуску радника в тестері він буде розташовуватися в каталозі каталог_данних_термінала / tester / Agent-127.0.0.1-3000 / MQL5 / Files. Отриманий файл вже можна завантажити в Statistica.
Приклад такого файлу прикладений в файлі MasterData.CSV. Дані були зібрані за допомогою тестера стратегій на EURUSD на ділянці з 1 серпня 2011 по 1 жовтня 2011 року на періоді H1.
Для завантаження файлу в Statistica робимо наступне.
- У Statistica відкрийте File, потім Open, виберіть тип файлу: Data files і відкривайте наш файл.
- У вікні Text File Import Type залиште Delimited і натисніть OK.
- У вікні включите підкреслені пункти.
- В поле Decimal separator character потрібно обов'язково поставити крапку незалежно від того, є вона там вже чи ні.
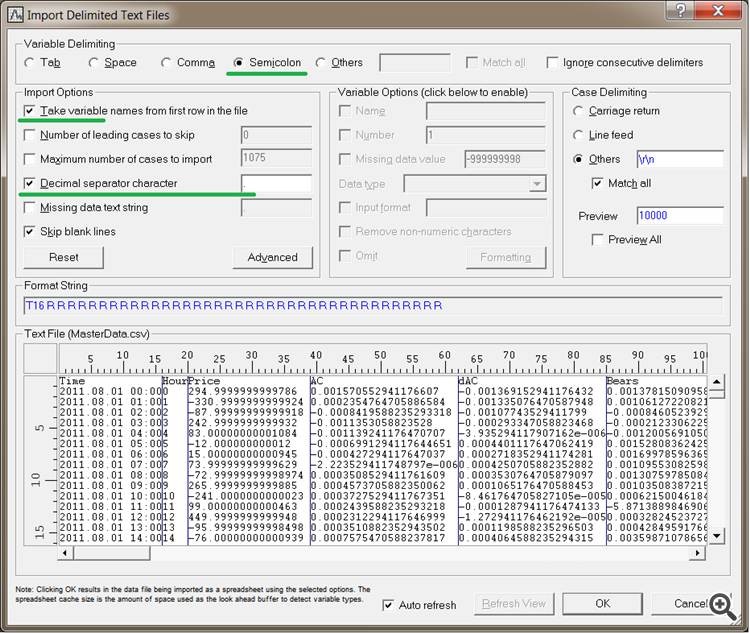
Мал. 1. Імпорт файлу в Statistica
Натисніть OK, отримуємо таблицю з нашими даними.
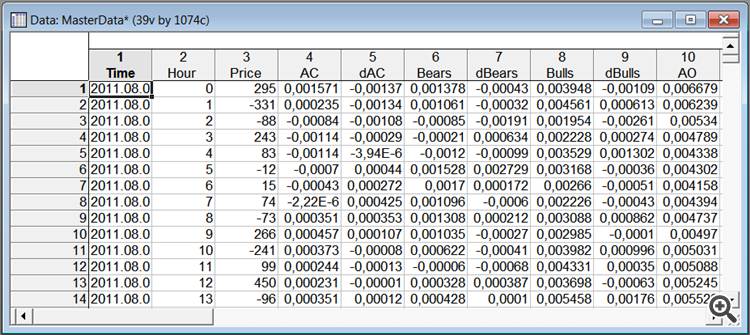
Мал. 2. База даних в Statistica
Тепер створимо групуються змінну на основі змінної Price.
Визначимо чотири групи на підставі того, куди пішла ціна:
- Вниз більше 200 пунктів;
- Вниз менше 200 пунктів;
- Вгору менше 200 пунктів;
- Вгору більше 200 пунктів.
Щоб додати нову змінну, клацніть правою кнопкою миші на заголовку стовпчика AC і виберіть Add Variable.
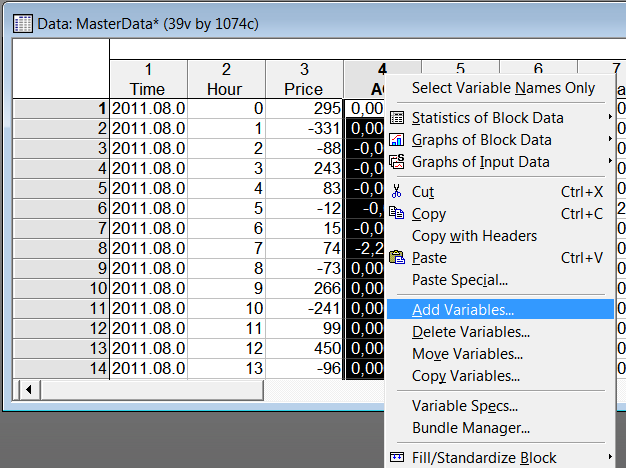
Мал. 3. Додавання нової змінної
У вікні, вкажіть назву для нової змінної Group і додайте формулу перекладу змінної Price в номери груп.
Формула має вигляд:
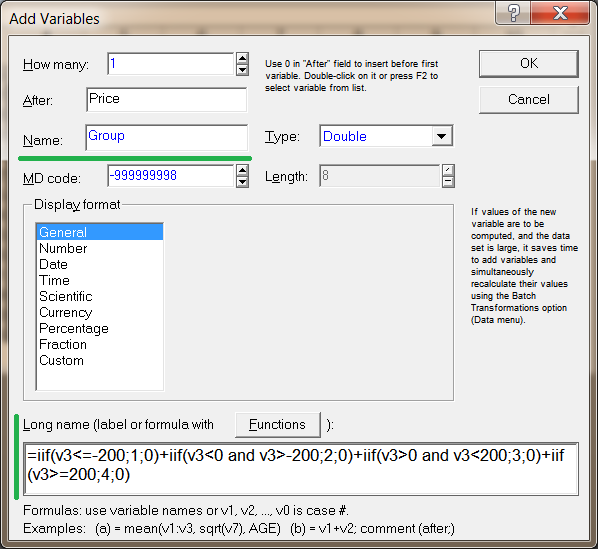
Мал. 4. Опис для змінної
Файл готовий для виконання дискримінантного аналізу. Приклад цього файлу прикладений в MasterData.STA.
2.2. Вибір кращих змінних
Запустіть Дискримінантний аналіз (Statistics-> Multivariate Exploratory Techniques-> Discriminant Analysis).
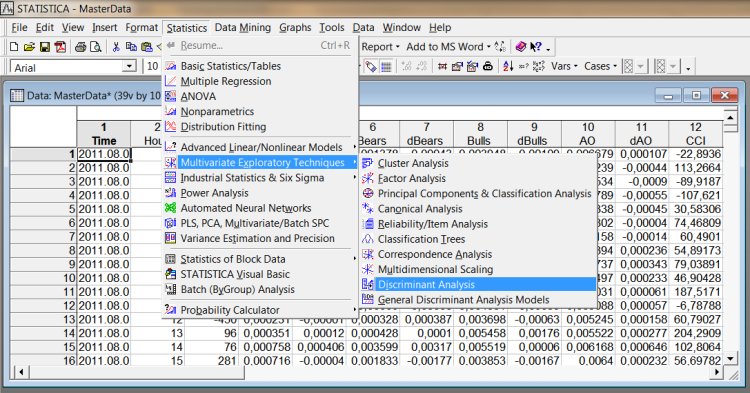
Мал. 5. Запуск дискримінантного аналізу
У вікні, натисніть кнопку Variables.
У першому полі виберіть групову змінну, у другому полі виберіть всі змінні, на основі яких ми будемо розділяти групи.
У нашому випадку: в першому полі змінна Group, у другому полі обрані всі змінні, отримані від індикаторів і додатково змінна Hour (година отримання даних).
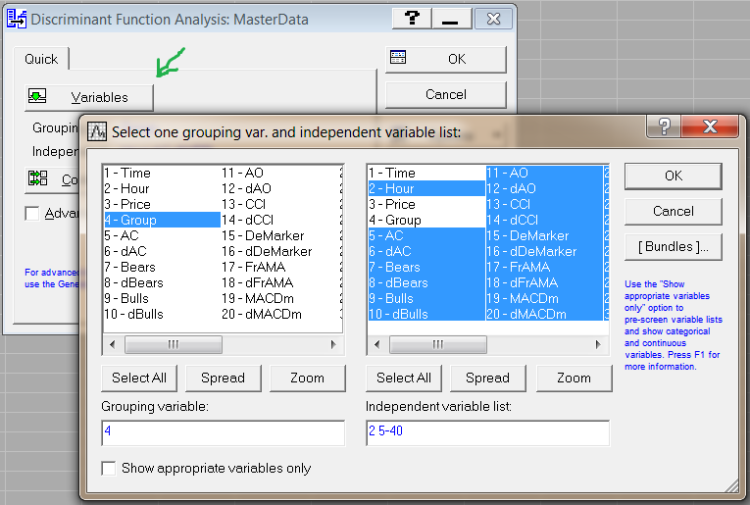
Мал. 6. Вибір змінних
Натисніть кнопку Select Cases (Малюнок 8). Відкриється вікно для вибору випадків (рядків даних), які ми будемо використовувати для діскрімінатного аналізу. Увімкніть пункти, зазначені на наступному знімку (Малюнок 7).
Зазначимо для аналізу тільки перші 700 випадків. Решта будемо використовувати потім для тестування отриманої прогностичної моделі. Номери випадків задаються через змінну V0. Вказавши тут випадки, ми задали вибірку навчальних даних для ДА.
Далі натисніть OK.
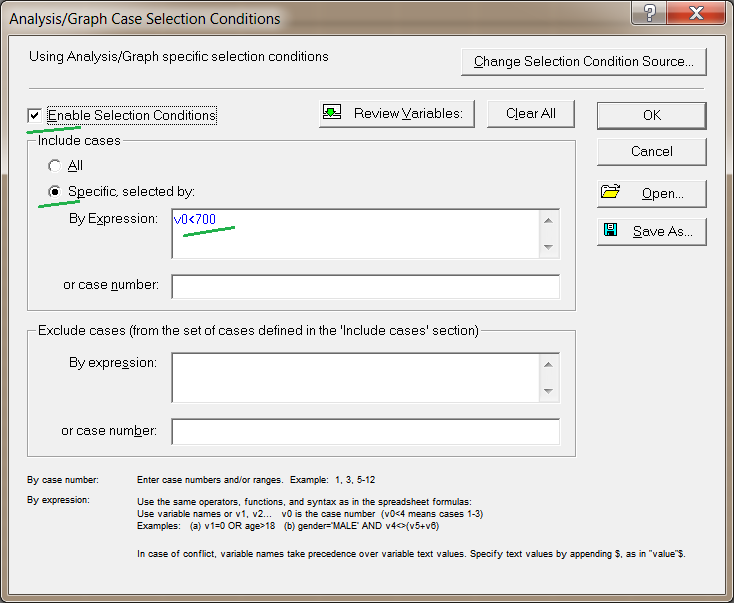
Мал. 7. Визначення навчальної вибірки
Тепер виберемо групи, для яких ми будемо будувати прогностичну модель.
Зупинимося тут на наступному моменті. Одним зі слабких місць ТАК є чутливість до викидів в даних. Рідкісні, але сильні події, в нашому випадку скачки ціни, можуть спотворити модель. Наприклад, після виходу якої-небудь несподіваної новини на ринку стався сильний рух, що тривало кілька годин. У цьому випадку значення технічних індикаторів мали малу значимість в прогнозі, але ТАК припише їм Надзвичайно важливим є було сильне зміна ціни. Тому перед виконанням ТАК бажано перевіряти дані на наявність таких викидів.
У нашому прикладі для виключення викидів виберемо для аналізу тільки групи 2 і 3. Оскільки в групах 1 та 4 відбулися важливі зміни ціни, то, можливо, там є і викиди в значеннях індикаторів.
Отже, натисніть кнопку Codes for grouping variable (Малюнок 8). Тут вкажіть номери груп, які ми відправимо на аналіз.
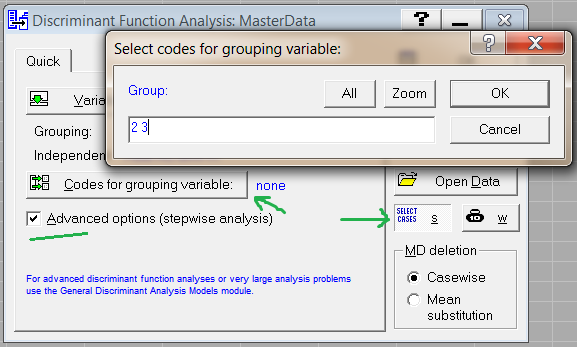
Мал. 8. Вибір груп для аналізу
Увімкніть пункт Advanced options. Це дасть доступ до покрокового аналізу даних (stepwise analysis), який ми будемо використовувати в подальшому.
Далі натисніть OK, щоб запустити ТАК.
Можливо, з'явиться повідомлення, як на малюнку нижче. Це означає, що якась із обраних змінних є надмірною і в значній мірі обумовлена іншими змінними. Наприклад, є сумою двох інших змінних.
Для потоку даних з індикаторів це цілком можливо. Наявність таких змінних знижує якість аналізу. Їх слід прибрати. Для цього потрібно повернутися до вікна вибору змінних для ДА і, послідовно додаючи змінні і повторюючи початок ТАК, визначити надлишкові змінні.
Мал. 9. Повідомлення про низькому значенні толерантності
Далі відкриється вікно вибору методу ТАК (Малюнок 10). Вкажіть тут в випадаючому списку пункт Forward Stepwise (покроковий аналіз з включенням). Оскільки значення індикаторів мають низьку прогностичну значимість, то краще використовувати покроковий аналіз змінних (Stepwise analysis). Тоді модель поділу груп буде автоматично будуватися по кроках.
Точніше, на кожному кроці проглядаються всі змінні, і знаходиться та з них, яка вносить найбільший вклад в відмінність між групами. Ця змінна включається в модель на даному етапі, і відбувається перехід до наступного кроку. Так послідовно будуть обрані змінні, які найкраще поділяють вибірку даних.
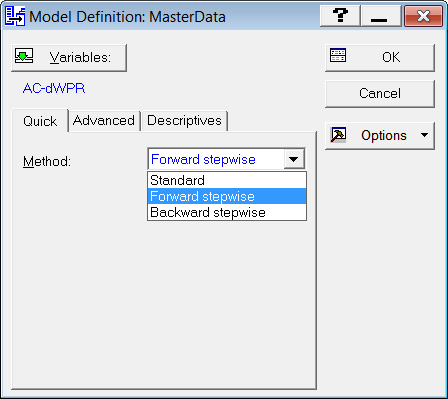
Мал. 10. Вибір методу
Натисніть OK і відкриється вікно, що інформує про те, що ТАК успішно виконаний.
Мал. 11. Вікно результатів ТАК
Натиснувши кнопку Summary: Variables in the model, ми побачимо список змінних, які були включені в модель на основі покрокового аналізу. Ці змінні найкращим чином поділяють наші групи. Зверніть увагу, що червоним кольором виділені змінні, які поділяють групи з достовірністю більше 95% (p <0.05). Достовірність поділу інших змінних гірше. Допустимо використовувати в моделі змінні, що розділяють групу з достовірністю менше 95%.
Однак, «золоте правило» статистики каже, що слід використовувати змінні мають достовірність понад 95%. Тому давайте виключимо з аналізу змінні, що не виділені червоним. Виключимо змінні: dBulls, Bulls, FrAMA, Hour. Для цього повернемося до вікна, де ми вибрали Покроковий аналіз, і у вікні по кнопці Variables виключимо ці змінні.
Далі повторимо аналіз. Знову відкривши по кнопці Summary: Variables in the model, ми побачимо, що ще три змінні стали відзначені, як малозначні. Це: DeMarker, Stoch_s, AO. Також виключимо ці змінні з аналізу.
У підсумку ми отримаємо модель, засновану на змінних, достовірно розділяють групи (p <0.01).
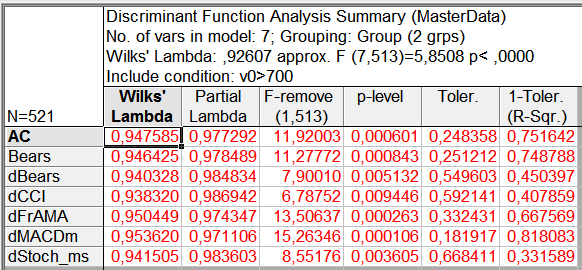
Мал. 12. Змінні, що увійшли в модель
Таким чином, в нашому прикладі з 37 змінних було залишено тільки сім найбільш значущих для прогнозу.
Такий підхід дозволяє вибирати головні показники з технічного аналізу для подальшої побудови власних торгових систем, в тому числі, з використанням нейронних мереж.
2.3. Аналіз отриманої моделі і її перевірка на тестових даних
Після виконання ТАК ми отримали прогностичну модель і результат її використання на навчальних даних.
Щоб подивитися модель і успішність поділу груп перейдіть на закладку Classification.
Мал. 13. Закладка Classification
Натисніть кнопку Classification matrix, щоб побачити таблицю з результатами застосування моделі до навчальних даних.
У рядках вказано справжню кількість випадків в кожній групі. У стовпчиках наведено кількість випадків з передбаченою приналежністю до груп згідно розрахованої моделі. Зеленим кольором я зазначив осередки з правильними прогнозами і червоним з неправильними.
У першому стовпчику приведена точність передбачення в%.
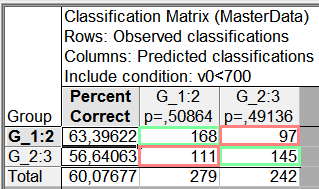
Мал. 14. Класифікація навчальних даних
Точність прогнозів (Total) на навчальній вибірці вийшла на рівні 60%.
Перевіримо модель на тестових даних. Для цього по кнопці Select (Малюнок 13) вкажіть v0> 700, модель буде перевірена на діапазоні даних, не використаних для побудови моделі.
Вийшло таке:
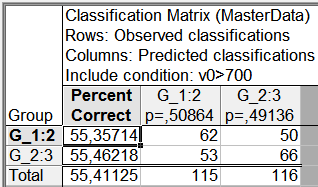
Мал. 15. Класифікація тестових даних
Сумарна точність прогнозів на тестовій вибірці вийшла теж на рівні 55%. Це є досить хорошим рівнем для ринку FOREX.
2.4. Будуємо торгову систему
Прогностична модель в ДА заснована на системі лінійних рівнянь, за якими розраховується приналежність значень показників до тієї чи іншої групи.
Щоб отримати опис цих функцій, перейдіть на закладку Classification у вікні результатів ТАК (рисунок 13) і натисніть кнопку Classification functions. Відкриється вікно з таблицею, що містить коефіцієнти дискримінантних рівнянь.
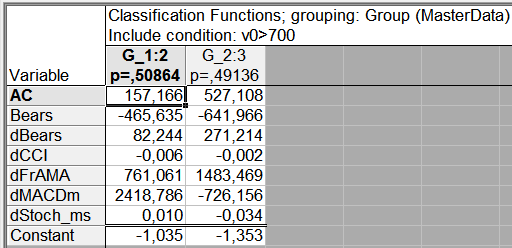
Мал. 16. дискримінантного рівняння
На основі таблиці побудуємо систему з двох рівнянь:
Для використання цієї моделі потрібно підставити значення індикаторів в рівняння і обчислити значення Group.
Прогноз буде ставитися до тієї групи, значення Group для якої буде найбільше. Згідно нашого прикладу, якщо Group2 більше Group3, то передбачається, що протягом наступної години цінової графік буде найімовірніше рухатися вниз. Зворотний прогноз для випадку, якщо Group3 більше Group2.
Необхідно відзначити, що для нашого прикладу показники індикаторів і період аналізу були обрані порівняно довільно. Але навіть цих даних було досить, щоб показати можливості і потужність ТАК.
Висновок
Дискримінантний аналіз є корисним інструментом в додатку до ринку FOREX. Він може бути використаний для пошуку і перевірки оптимального набору змінних, що дозволяють відносити спостерігаються значення індикаторів до різними прогнозами. Також він може бути використаний для побудови прогностичних моделей.
Моделі, одержувані в результаті дискримінантного аналізу, можуть бути легко вбудовані в радники, для цього не потрібно істотний досвід у програмуванні. Сам дискримінантний аналіз також порівняно простий у використанні. Представлене покроковий опис цілком достатньо, щоб проводити аналіз власних даних.
Детальніше про дискримінантному аналізі можна прочитати в електронному підручнику у відповідному розділі.